The Temporal Consistency Challenge From Optical Flow to Spatiotemporal AI in Video Restoration
A technical deep dive into the definitive barrier separating amateur tools from professional-grade video AI.
1. Introduction: The Flicker Problem and the Dimension of Time
We are witnessing a Cambrian explosion of generative AI. Image manipulation has reached remarkable maturity: removing unwanted objects from a photograph is now almost trivial, supported by tools ranging from Photoshop’s Generative Fill to open-source diffusion models. On static images, results are often visually flawless.
Naturally, expectations have shifted toward video.
From professional editors to everyday content creators, the demand is clear:
“One-click erase anything from video.”
Yet, reality lags behind the promise.
When current AI video tools are applied to dynamic footage—such as removing a logo from a panning shot or erasing a person walking across a textured background—the illusion quickly collapses. Instead of seamless restoration, the result is often plagued by shimmering textures, unstable edges, and chaotic motion artifacts.
In the visual effects industry, these failures are known as temporal artifacts. To end users, they appear as flicker, jitter, or “boiling” textures—rendering the output unusable for any professional purpose.
Why does this gap exist?
Why is image inpainting nearly solved, while video inpainting remains stubbornly difficult?
The answer lies in a fundamental distinction:
A video is not a collection of images.
It is a continuous spatiotemporal signal.
A single frame is two-dimensional.
A video exists in three dimensions: height × width × time.
The decisive barrier separating amateur video tools from professional-grade AI is not spatial quality, but temporal consistency—the ability to maintain coherent structure and motion across frames.
This article explores that barrier in depth, tracing the evolution of video restoration from optical flow to modern spatiotemporal AI, and explaining why temporal consistency remains the central challenge in automated video repair.

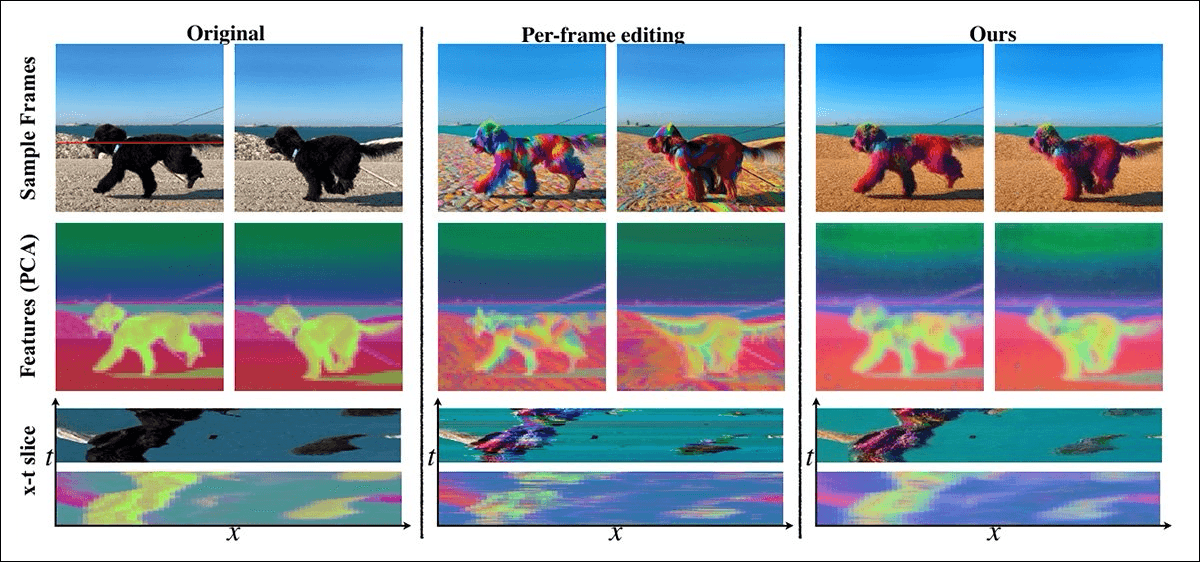
2. The Trap of Per-Frame Inpainting
Most failed AI video tools share the same flaw: per-frame inpainting.
This approach applies a powerful image model independently to each frame of a video, treating time as irrelevant. Each frame may look acceptable on its own, but the sequence as a whole collapses.
Consider an analogy.
Imagine asking a skilled painter to repaint a watermarked region across 100 consecutive frames of a video showing rippling water. The painter is forbidden from seeing the frames before or after the one they are currently working on.
In frame 10, they paint a small wave crest.
In frame 11, they imagine a smooth reflection.
In frame 12, they add a shadow from a passing cloud.
Each frame, viewed alone, is plausible.
Played in sequence, the region mutates chaotically thirty times per second.
This is the essence of flicker.
The model has no memory of the immediate past and no awareness of the immediate future. It cannot respect motion continuity, lighting evolution, or physical plausibility.
Per-frame inpainting fails not because the image quality is poor, but because time is ignored.

3. How Temporal Consistency Is Measured
Temporal consistency is not a subjective aesthetic judgment. In professional research and engineering workflows, it is quantified using motion-aware and perceptual metrics.
Common evaluation methods include:
Feature-level similarity across frames, such as VGG-based cosine similarity, to assess semantic stability over time.
Temporal Flicker Index (TFI), measuring high-frequency temporal variations in reconstructed regions.
Optical-flow residual consistency, where instability appears as errors between predicted motion and reconstructed pixels.
Warping error metrics, evaluating how well reconstructed content aligns when propagated across frames.
No single metric fully captures human perception, but together they clearly separate temporally coherent models from frame-independent approaches.

4. Era 1.0: Optical Flow and Motion Propagation
Before deep learning reshaped computer vision, video restoration relied heavily on optical flow.
Optical flow estimates how pixels move between consecutive frames, producing a vector field that describes motion direction and magnitude. Early video inpainting systems used this information to propagate known background pixels from adjacent frames into occluded regions.
This approach marked a significant improvement over per-frame editing and works well in simple scenarios, such as slow camera pans over static scenes.
However, it rests on a fragile assumption: that optical flow estimation is accurate.
In real-world footage, this assumption frequently breaks down.
Optical flow struggles with:
Occlusions, where background pixels disappear behind moving objects.
Complex motion, such as smoke, fire, water, or foliage.
Large displacements, caused by fast camera movement or cuts.
When flow estimation fails, errors are propagated across frames, producing warped textures and unstable artifacts. Optical flow improved temporal coherence, but could not guarantee it.

5. Era 2.0: Spatiotemporal Deep Learning
The modern shift in video restoration began when researchers stopped treating time as auxiliary information and instead modeled it explicitly.
This marked the transition from “2D + time” thinking to true spatiotemporal modeling.
5.1 3D Convolutional Networks
Early deep learning approaches introduced 3D convolutional neural networks (3D CNNs). These models process stacks of frames using volumetric filters, allowing spatial and temporal features to be learned jointly.
While effective for short sequences, 3D CNNs face limitations:
High computational cost
Limited receptive fields
Difficulty modeling long-range temporal dependencies
5.2 Attention and Transformer-Based Models
A more profound breakthrough emerged from attention mechanisms, adapted from natural language processing.
Transformer-based architectures, such as FuseFormer, allow models to selectively attend to relevant regions across many past and future frames. Instead of copying pixels blindly, the model learns to ask:
“Which moments in the video’s history best explain what belongs here?”
By attending to consistent background structures while ignoring transient foreground motion, these models achieve stable, flicker-free reconstruction.
Temporal coherence becomes an emergent property of learned spatiotemporal reasoning.

6. Practical Implementations in Industry and Open Source
Spatiotemporal consistency is not confined to research papers. It underpins many real-world systems.
Examples include:
RIFE / DAIN
Originally developed for frame interpolation, these models emphasize motion-aware temporal smoothness and are often reused in restoration pipelines.
Adobe After Effects with Mocha AE
Professional workflows combine optical flow, planar tracking, and manual constraints to maintain temporal coherence.
Runway ML Gen-2 and Pika
Generative video platforms exploring transformer- and diffusion-based spatiotemporal generation.
Open-source research implementations, such as FuseFormer-based video inpainting frameworks.
Across these systems, the conclusion is consistent: video restoration must reason across time to succeed.
7. Era 3.0: Generative Video Diffusion
The next frontier is video diffusion models.
While attention-based systems excel at maintaining consistency in existing textures, diffusion models enable the synthesis of entirely new content that remains stable over time.
Recent research incorporates temporal adversarial losses, where discriminator networks evaluate short video segments instead of individual frames. These discriminators penalize flicker, jitter, and motion inconsistency, forcing the generator to internalize spatiotemporal structure.
The model no longer merely fills holes—it learns to generate a coherent temporal reality.

8. Open Challenges Ahead
Despite progress, significant challenges remain:
Long-duration consistency
Maintaining identity and structure across minutes or hours of video remains unresolved.
Semantic-level temporal reasoning
Future systems must encode physical and logical priors: objects do not pass through walls, shadows obey lighting geometry, and liquids follow gravity.
Real-time constraints
Achieving temporal stability under low-latency requirements—such as mobile devices or live streaming—demands lightweight yet expressive models.
Temporal consistency is not a solved problem, but an evolving frontier.
9. Ethical Considerations and Responsible Deployment
Powerful video restoration capabilities raise legitimate concerns around misuse and deepfake generation.
Responsible deployment requires:
Clear usage policies
Legal guidance and fair-use awareness
Integration with content provenance and digital watermarking systems
Advancing video AI must go hand in hand with safeguards that preserve trust in visual media.

Conclusion: The New Standard
The era of accepting flickering, unstable automated video repairs is ending.
Professional video AI is not defined by how good a single frame looks, but by how coherently frames evolve over time. Temporal consistency has become the defining standard.
Understanding this challenge clarifies the difference between novelty tools and production-grade systems. As spatiotemporal models continue to mature—from optical flow to attention mechanisms and diffusion—the boundary between automated video restoration and human-level results is rapidly dissolving.
Temporal consistency is no longer an enhancement.
It is the line that separates experimental video AI from professional systems.
These challenges are not theoretical. They directly shape how modern video restoration systems are designed and deployed in real-world applications.
This requirement becomes especially apparent in automated watermark removal tasks, where even minor temporal artifacts are immediately visible during playback.
One practical implementation of these concepts can be seen in modern AI-based video watermark removal pipelines, where temporal consistency is critical to avoid flicker across frames.
References
Foundational Surveys & Metrics
Prokudin, S., et al. Deep Video Inpainting: A Survey. arXiv:2201.11258
Lai, W.-S., et al. Learning Blind Video Temporal Consistency. ECCV 2018
Flow-Based Approaches
Gao, Y.-K., et al. Flow-edge Guided Video Completion. ECCV 2020
Spatiotemporal Transformers
Liu, R., et al. FuseFormer. ICCV 2021
Zeng, Y., et al. Learning Joint Spatial-Temporal Transformations for Video Inpainting. ECCV 2020
Video Diffusion Models
Blattmann, A., et al. Align Your Latents. CVPR 2023
Industry Research
Google Research. Lumiere: A Space-Time Diffusion Model for Video Generation.
Meta AI. Emu Video.
Runway Research. Gen-2.